Optimize Product Development with Teamcenter
Make your manufacturing and Engineering-to-Order projects smoother with Siemens Teamcenter. Teamcenter helps you work better together, cut costs, and scale as your needs change.

The CLEVR way: From vision to value
At CLEVR, we don’t just implement technology—we enable transformation. Our approach ensures that companies don’t just digitize but truly evolve by embedding Low Code, PLM, and MOM solutions in a structured, scalable way.
Key NX Features
Integrated Design, Simulation, and Manufacturing
Combine all aspects of product development into a single environment, reducing design iterations and accelerating time-to-market.
Integrated Design, Simulation, and Manufacturing
Combine all aspects of product development into a single environment, reducing design iterations and accelerating time-to-market.

Integrated Design, Simulation, and Manufacturing
Combine all aspects of product development into a single environment, reducing design iterations and accelerating time-to-market.

Integrated Design, Simulation, and Manufacturing
Combine all aspects of product development into a single environment, reducing design iterations and accelerating time-to-market.


Why CLEVR?

- Proven Expertise: 20 years of low code experience, 3,500+ applications delivered.
- Tailored Solutions: A unique "Vision to Value" methodology ensuring measurable results.
- Global Recognition: Mendix Platinum Partner, awarded Best BNL Partner 2024.
- Customer Satisfaction: Score of 8.8 out of 10, reflecting our commitment to excellence.
- Certified Professionals: The largest team of Mendix expert developers and MVPs.
- Proven Expertise: 20 years of low code experience, 3,500+ applications delivered.
Compare licensing plans
Advanced
Create and edit designs of typical 3D parts and assemblies and more with NX X Design Standard.
Standard
Create and edit designs of typical 3D parts and assemblies and more with NX X Design Standard.
Premium
Create and edit designs of typical 3D parts and assemblies and more with NX X Design Standard.
Verhalen van onze klanten
Bekijk hoe bedrijven zoals het uwe veranderen met CLEVR.
De branchekennis en ervaring van CLEVR met het automatiseren van complexe groothandelsprocessen hebben ons geholpen een toekomstbestendige product lifecycle management (PLM) omgeving te creëren. We zijn zeer tevreden over de samenwerking. Het klikte vanaf het eerste moment. We houden elkaar scherp en maken goed gebruik van elkaars aanvullende expertise.


CLEVR stelde nieuwe manieren voor om Teamcenter te gebruiken die we nog niet eerder hadden gezien.


Mendix stelt ons in staat om ons snel aan te passen aan nieuwe wettelijke eisen en beveiligingsupdates.

Ik geloof dat we samen op verschillende manieren aan morgen bouwen. Wij proberen de toekomst vorm te geven door apparatuur te leveren voor de productie van groene waterstof, en CLEVR helpt ons met informatietechnologie om dat efficiënt te doen.



Find out how CLEVR can drive impact for your business
We try to build the future by providing equipment to produce green hydrogen to enable the green transition.
Related Resources

Elk jaar, Siemens Realize LIVE brengt fabrikanten, ingenieurs en technologieleiders samen om te onderzoeken waar de industrie naartoe gaat en hoe die toekomst in de praktijk vorm krijgt. Productupdates, roadmap-aankondigingen en technologische hoogtepunten tijdens sessies, klantverhalen en partnerdiscussies hebben dit jaar aangetoond dat productie niet langer draait om het optimaliseren van individuele technologieën. Het gaat om het verbinden van systemen, intelligentie en mensen tot één coherent geheel. Deze verschuiving is met name zichtbaar in hoe AI in de productie evolueert van geïsoleerde use cases naar verbonden, operationele systemen.
Deze verschuiving bouwt voort op een langdurige ambitie binnen de industrie om verbonden omgevingen te creëren waar gegevens naadloos stromen tussen PLM, ERP, MES en leveranciersnetwerken, wat de efficiëntie, zichtbaarheid en besluitvorming verbetert. De introductie van AI breidt dit landschap verder uit, niet alleen door het potentieel voor automatisering en inzicht te vergroten, maar ook door kritische vragen op te roepen over hoe deze mogelijkheden kunnen worden vertaald naar meetbare en schaalbare operationele waarde.
Hier zijn de 4+1 ideeën die bepalend waren voor Realize LIVE 2026 en wat ze betekenen voor de toekomst van de productie.
1. AI wordt operationeel, niet experimenteel
Jarenlang is AI gepositioneerd als een krachtig hulpmiddel, dat individuen ondersteunt via copilots, voorspellingen en inzichten. Op Realize LIVE 2026 werd duidelijk dat deze fase evolueert naar uitvoering op schaal.
AI-use cases in de productie verschuiven van assistentie naar orkestratie binnen echte workflows. In plaats van geïsoleerd te reageren op prompts, wordt het ingebed in processen waar het beslissingen kan ondersteunen, systemen kan coördineren en activiteiten met meerdere stappen gedurende de hele levenscyclus kan automatiseren.
De introductie van Intelligence Center X signaleert deze overgang expliciet. Door bedrijfsgegevens, levenscycluscontext en workflows te verbinden in een gecontroleerde omgeving, kunnen organisaties AI-agenten inzetten naast mensen als onderdeel van een hybride personeelsbestand, en zo overstappen van geïsoleerde pilots naar uitvoering op productieniveau met traceerbaarheid en controle.
De vraag is niet langer of AI werkt. Het gaat erom hoe organisaties het inbedden in verbonden systemen en gestructureerde workflows, met de governance die nodig is om consistente, meetbare en schaalbare waarde te leveren.
2. Verbonden systemen zijn belangrijker dan geïsoleerde innovatie
Ondanks voortdurende investeringen in digitale transformatie, staan veel fabrikanten nog steeds voor uitdagingen als het gaat om het opschalen van innovatie binnen de hele onderneming. Het onderliggende probleem is niet een gebrek aan technologie, maar een gebrek aan connectiviteit, met name over de integratielagen van PLM, ERP en MES die essentieel zijn om schaalbare AI in de productie mogelijk te maken.
Binnen organisaties blijven systemen gefragmenteerd, gegevens zijn verspreid over silo's en AI-initiatieven worden vaak geïntroduceerd als geïsoleerde pilots. Hoewel deze inspanningen lokale verbeteringen opleveren, vertalen ze zich zelden in meetbare impact over de gehele productlevenscyclus.
In de maakindustrie zijn ontwerp, engineering, productie en service inherent onderling afhankelijk. Het optimaliseren van individuele componenten op zichzelf leidt daarom niet tot systemische verbetering. Het verbinden van bestaande systemen tot een samenhangende digitale draad doet dat wel.
Dit is precies wat onze CEO, Tim Claes, benadrukte in zijn keynote, waarbij hij deze uitdaging en kans schetste aan de hand van wat hij definieerde als de Heilige Drie-eenheid van de Maakindustrie:
- PLM als de ruggengraat voor productgegevens en de digitale draad
- Smart factory als de laag die IT en OT verbindt, waardoor zichtbaarheid en controle over alle operaties mogelijk wordt
- Low code en AI als de orkestratielaag die systemen, workflows en besluitvorming met elkaar verbindt
Individueel levert elk van deze domeinen waarde op. De echte impact ontstaat echter wanneer ze functioneren als onderdeel van een verbonden systeem. Dit wordt steeds meer de aanpak die fabrikanten hanteren om concurrerend en relevant te blijven in een snel evoluerende markt.
3. Duurzaamheid wordt onderdeel van alledaagse engineering
Een ander sterk signaal van Realize LIVE was de verschuiving in hoe organisaties duurzaamheid in productie en compliance benaderen.
Regelgeving wordt strenger, met name in Europa, waar kaders zoals CSRD, REACH en opkomende vereisten zoals het Digitaal Productpaspoort organisaties dwingen gedetailleerd inzicht te geven in materialen, inkoop en milieu-impact over de gehele waardeketen. Tel daarbij op de druk waarmee specifieke industrieën zoals lucht- en ruimtevaart en defensie te maken hebben om hun marges te verbeteren, en de strengere compliance-eisen en groeiende verwachtingen van OEM's en partners, dan kan duurzaamheid niet langer een aparte rapportageactiviteit zijn, maar een factor die direct van invloed is op kosten, risico's en concurrentievermogen.
Tijdens zijn keynote, Gerrit Kiefer, onze Head of Solutions en Customer Success Management in Duitsland, demonstreerde hoe deze transitie in de praktijk al plaatsvindt. Samen met tec4U, liet hij zien hoe compliance en duurzaamheid direct in engineeringworkflows kunnen worden geïntegreerd, waardoor organisaties in staat zijn om:
- Regelgevende vereisten direct integreren in PLM- en ontwerpomgevingen
- Volledige traceerbaarheid van materialen, componenten en leveranciers gedurende de gehele productlevenscyclus waarborgen
- Handmatige inspanningen bij compliancerapportage verminderen door geautomatiseerde gegevensvastlegging en -validatie
- Risico's en compliance-lacunes eerder identificeren in de ontwerpfase, waar ze nog efficiënt kunnen worden aangepakt
- Kosten-, duurzaamheids- en engineeringbeslissingen op elkaar afstemmen door alle relevante gegevens beschikbaar te maken in één verbonden workflow
- De tijd tot compliance versnellen met behoud van controle en auditbaarheid over processen
4. De opkomst van de orchestratielaag
Met de introductie van Intelligence Center X heeft Siemens duidelijk een strategische focus geformuleerd op het opzetten van een orchestratielaag die bedrijfsgegevens, workflows en AI-agenten verbindt tot een samenhangend en schaalbaar systeem. Een orchestratielaag fungeert als de architectonische component die data-orkestratie, workflowcoördinatie en AI-uitvoering over systemen heen mogelijk maakt.
De implicatie voor fabrikanten is aanzienlijk. De meesten hebben al zwaar geïnvesteerd in kernsystemen zoals PLM, ERP en MES. Dus in plaats van nieuwe systemen te bouwen, kunnen ze activeren en verbinden wat al bestaat.
Bij CLEVR, pleiten we al geruime tijd dat grootschalige 'rip and replace'-strategieën niet langer duurzaam, noch noodzakelijk zijn. Na verloop van tijd zijn engineeringlogica, domeinkennis en procesintelligentie diep ingebed geraakt in bestaande systemen. Het vervangen van deze fundamenten zou niet alleen risico's met zich meebrengen, maar ook waardevol intellectueel kapitaal weggooien.
In plaats daarvan kunnen fabrikanten een orchestratielaag introduceren bovenop hun huidige landschap, waardoor ze workflows kunnen verbinden, intelligentie kunnen inbedden en mogelijkheden kunnen uitbreiden zonder te verstoren wat al werkt.
4+1. Technologie is klaar. Organisaties niet
Als er één ding is dat we veilig kunnen afleiden uit Realize LIVE 2026, dan is het dat de uitdaging niet langer technologisch is. Fabrikanten hebben vandaag de dag toegang tot geavanceerde PLM-platforms, verbonden fabriekssystemen, low-code omgevingen en steeds krachtigere AI-mogelijkheden. De bouwstenen voor transformatie zijn al aanwezig.
Toch stagneren veel AI-adoptie-initiatieven in de productie. Bij CLEVR zien we dit patroon dagelijks bij organisaties. Workflows die niet volledig begrepen of in kaart gebracht zijn, beslissingslogica die impliciet blijft, ongestructureerde data, of niet verbonden op een manier die betrouwbare, systeemoverkoepelende uitvoering mogelijk maakt.
Intelligentie inbedden in workflows vereist meer dan implementatie. Het vereist duidelijkheid over hoe beslissingen worden genomen, waar de verantwoordelijkheid ligt en hoe mensen en systemen met elkaar omgaan.
Dit betekent dat de volgende grens die moet worden aangepakt van organisatorische aard is. Fabrikanten moeten workflows ontwerpen die duidelijk gedefinieerd zijn, beslissingen die expliciet gestructureerd zijn, en governance-modellen die kunnen worden vertaald naar uitvoerbare logica. Alleen dan kunnen AI-agenten betrouwbaar functioneren, autonome beslissingen nemen binnen gedefinieerde grenzen, en schalen over de hele onderneming met consistentie en controle.
5 acties die fabrikanten vandaag kunnen ondernemen
Ten eerste, moet de focus verschuiven van het toevoegen van meer tools naar het verbinden van bestaande tools. De meeste organisaties hebben de kernsystemen al in huis. De echte kans ligt in het koppelen ervan tot een coherente digitale draad doorheen ontwerp, engineering, productie en service.
Ten tweede, moeten AI-initiatieven verder gaan dan experimenteren. In plaats van geïsoleerde pilots moet de nadruk liggen op het inbedden van intelligentie in echte workflows waar het meetbare impact kan leveren. Dit vereist duidelijke governance, gedefinieerde beslissingsgrenzen en een sterke orkestratielaag.
Ten derde, moeten transformatiestrategieën pragmatischer worden. Grootschalige, meerjarige vervangingsprogramma's zijn steeds moeilijker te rechtvaardigen. Een 'leave and layer'-benadering stelt organisaties in staat om te beginnen met wat ze hebben, dit intelligent uit te breiden en stapsgewijs waarde te leveren.
Ten vierde, mogen duurzaamheid en compliance niet langer aan de zijlijn staan. Door deze vereisten direct te integreren in engineering- en productontwikkelingsprocessen, kunnen fabrikanten ze omzetten in een concurrentievoordeel in plaats van een beperking.
Tot slot, moeten organisaties opnieuw nadenken over hoe mensen en technologie samenwerken. Naarmate AI wordt ingebed in de bedrijfsvoering, zullen nieuwe rollen, verantwoordelijkheden en manieren van werken ontstaan. Dit bewust ontwerpen is cruciaal voor het succes van de transformatie.
Denk groot met een duidelijke visie voor uw organisatie, begin klein met één workflow die onmiddellijke waarde levert, en schaal snel zodra de aanpak effectief blijkt.

Kortere ontwerpprocessen, geautomatiseerde engineeringworkflows en een minimum aan handmatig werk. Het zijn de logische vervolgstappen in de digitalisering van de maakindustrie. Door data, systemen en processen slim te verbinden, stijgen de efficiëntie en de kwaliteit van de besluitvorming. Met de komst van AI in de fabriek wordt die belofte nu exponentieel versterkt.
In een verbonden productie-ecosysteem, waar gegevens stromen tussen PLM, ERP, MES en leveranciersnetwerken, heeft AI het potentieel om deze gegevens te gebruiken om niet alleen taken, maar ook beslissingen te automatiseren. Kosten optimaliseren, de CO2-voetafdruk in de productie verminderen en operationele gegevens van context voorzien, zijn slechts enkele manieren waarop AI een nieuw niveau van inzicht mogelijk maakt binnen het Siemens Teamcenter-ecosysteem. Een enorme kans voor een sector die lange tijd heeft geworsteld met gefragmenteerde gegevens en beperkt inzicht.
Dit roept een belangrijke vraag op voor fabrikanten: Waar bevindt enablement-software zich binnen dit spectrum, en hoe voorbereid zijn organisaties om naar deze toekomst toe te bewegen?
AI-copilots in software voor product cost management
Siemens zet al actieve stappen richting deze autonome toekomst door copilots te introduceren in zijn ecosysteem, waarbij product cost management een van de eerste gebieden is waar deze intelligentie direct van invloed is op de besluitvorming.
Hoewel nog in een pilotfase, laten deze copilots nu al zien hoe AI taken op het gebied van kostenengineering kan stroomlijnen door functies mogelijk te maken zoals geautomatiseerde onderdelenmatching, directe generatie van stuklijsten (Bill of Materials) en proceslijsten (Bill of Processes), en versnelde 'wat als'-scenario simulaties.
In plaats van tijd te besteden aan het bouwen en onderhouden van modellen, kunnen teams zich voortaan richten op het evalueren van scenario's, het vergelijken van alternatieven en het nemen van beslissingen. Complexe analyses die voorheen aanzienlijke handmatige inspanning vereisten, kunnen nu sneller en met grotere consistentie worden uitgevoerd.
Voor organisaties betekent dit:
- Snellere evaluatie van ontwerp- en inkoopopties
- Minder afhankelijkheid van handmatige gegevensvoorbereiding
- Consistentere en betrouwbaardere kostenmodellen
- De mogelijkheid om meer scenario's in minder tijd te verkennen
AI-ready productiegegevens opbouwen voor product cost management en duurzaamheid
Voor productieorganisaties is een solide basis cruciaal. Om AI veilig te kunnen operationaliseren, moeten bedrijven eerst hun gegevens operationaliseren. Ongestructureerde gegevens leiden tot gefragmenteerde workflows, en gefragmenteerde workflows zijn een van de belangrijkste redenen waarom AI-initiatieven niet verder komen dan de pilotfase. Hier zet Siemens een volgende belangrijke stap. Door de manier waarop bedrijfsgegevens worden opgeslagen en gestructureerd te verbeteren, versterkt het de onderliggende basis die nodig is om die mogelijkheden op schaal effectief te maken.
1. Cloud voor schaalbaar AI-gestuurd product cost management
Naarmate AI evolueert naar meer autonome en agent-gestuurde workflows, hebben organisaties platforms nodig die schaalbaar, verbonden en continu geüpdatet zijn. Cloudomgevingen bieden die basis en daarom is de mogelijkheid om bedrijfsomgevingen naar de cloud te migreren een essentieel element.
Met de nieuwste verbeteringen in Teamcenter Product Cost Management kunnen bestaande gebruikers hun waardevolle plugins en aangepaste kostenoverzichten naar de cloudomgeving brengen zonder de functionaliteit te verliezen waar ze van afhankelijk zijn. Dit stelt organisaties in staat om een grotere schaalbaarheid te bereiken, innovatiecycli te versnellen en operationele overhead te verminderen, terwijl ze een betrouwbare basis leggen voor geavanceerde analyses en AI-gestuurde beslissingsondersteuning op schaal.
2. Gebruikerservaring voor snellere kosten- en duurzaamheidsbeslissingen
Een gemoderniseerde gebruikersinterface vermindert frictie in dagelijkse workflows en verbetert de toegang tot relevante gegevens. In plaats van door complexe systemen te navigeren, kunnen gebruikers nu gemakkelijker de informatie vinden, interpreteren en ernaar handelen die ze nodig hebben. Verbeterde navigatie, gereorganiseerde lay-outs en intuïtievere toegang tot kernfunctionaliteiten zijn enkele voorbeelden van dergelijke verbeteringen, terwijl verbeterde zoekmogelijkheden en duidelijkere datavisualisatie teams in staat stellen efficiënter te focussen op het evalueren van kostendrijvers, het vergelijken van scenario's en het ondersteunen van beslissingen.
3. API's en dataklaarheid voor productie-intelligentie
Tot slot heeft Siemens belangrijke stappen gezet om verder te optimaliseren hoe systemen gegevens interpreteren en inzichten genereren, zodat bedrijfskennis niet alleen beschikbaar is, maar ook gestructureerd, verbonden en toegankelijk is, op een manier die geavanceerde analyses en schaalbare AI-gestuurde toepassingen mogelijk maakt.
Verbeterde rekenmogelijkheden en REST API -extensies maken automatisering, integratie met externe systemen en geavanceerdere rapportage en analyses mogelijk.
Verbeteringen in datamodellen, KPI-flexibiliteit en inzicht in productiekosten bieden een gedetailleerder en nauwkeuriger beeld van kostendrijvers en winstgevendheid.
Hoe CLEVR software voor product cost management en AI in de maakindustrie mogelijk maakt
Technologie alleen creëert geen intelligentie. Organisaties moeten nog steeds bepalen waar beslissingen worden genomen, welke gegevens deze moeten onderbouwen en hoe inzichten kunnen worden geïntegreerd in de dagelijkse bedrijfsvoering. Dit begint met het structureren van gegevens op een consistente en schaalbare manier, en ervoor zorgen dat product-, kosten- en operationele informatie gestandaardiseerd wordt over systemen heen.
Van daaruit kunnen workflows worden geautomatiseerd om bedrijfsregels, engineeringlogica en financiële modellen direct in processen te integreren, een basis waarop AI-modellen effectief kunnen voortbouwen, lerend van betrouwbare gegevens en inzichten leveren die nauwkeurig, bruikbaar en afgestemd zijn op de manier waarop de organisatie opereert.
Bij CLEVR, combineren we diepgaande branche-expertise met een team van specialisten in geavanceerde softwareoplossingen om fabrikanten te helpen deze mogelijkheden om te zetten in meetbare resultaten. Met meer dan 30 jaar ervaring in het leveren van op maat gemaakte technologische oplossingen binnen de maakindustrie, maritieme sector, lucht- en ruimtevaart en defensie, begrijpen we de realiteit van complexe, verouderde omgevingen en hoe deze te ontwikkelen.
Door toonaangevende platforms zoals Siemens en Mendix aan de context van elke organisatie aan te passen, werken we samen met onze klanten om domeinkennis, bedrijfsregels en engineeringlogica te integreren in schaalbare workflows, en deze te verrijken met AI waar dit de meeste waarde oplevert. In de praktijk betekent dit dat we gestructureerd kosten- en duurzaamheidsbeheer activeren, ondersteund door de governance en orkestratie die nodig zijn in een steeds complexere en datagedreven toekomst.
Naarmate product cost management zich blijft ontwikkelen en AI steeds meer wordt geïntegreerd in het digitale landschap, hebben fabrikanten de mogelijkheid om opnieuw te bekijken hoe inzichten over kosten, duurzaamheid en winstgevendheid worden gebruikt, en deze, met de juiste partner, om te zetten in krachtige beslissingsmotoren.

This blog is about the 'Workflow: The Ultimate Springboard for Intelligent Automation' video, presented by Daniel Dam from Mendix. You can watch the video here.
Workflows is a brand new technology being added to the Mendix ecosystem. Think of them like asynchronous long-lived microflows. Where a microflow is blocking and expected to complete in a few seconds, a workflow can span several days.
This makes them perfect for modeling and automating business processes in an intuitive way. They remind me of IFTTT but they’re much more powerful and less technical thanks to the Mendix platform.
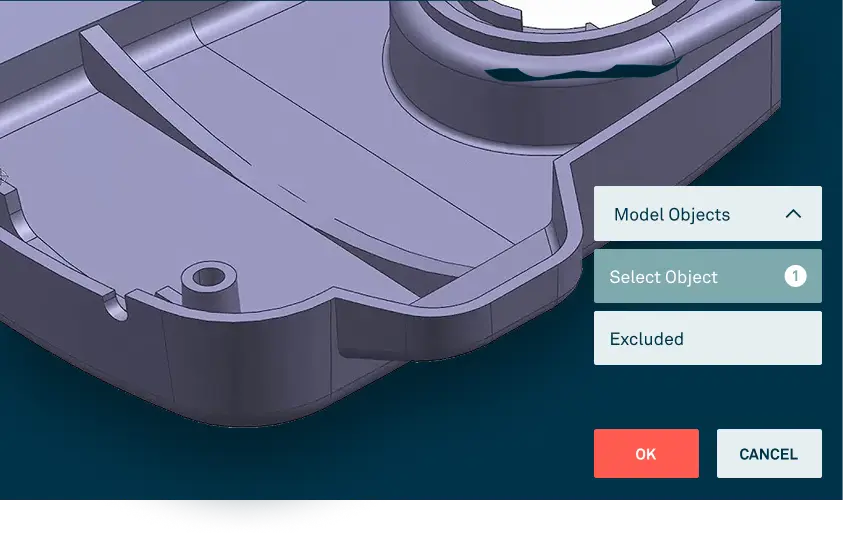
Unlike microflows which are modeled left-to-right, workflows have a preferred top-to-bottom direction. Similar to microflows, workflows have activities and conditions. Activities come in two types: user tasks, e.g. show a page; and system tasks, e.g. send an email. One important new feature is the ability to get a result from an open page based on which button is clicked to close the page. This will be great for building approval dialogs, as you can see from the screenshot.
{{cta('8876e954-dd4f-4149-851f-d6df8a06714e')}}Unlike microflows which are modeled left-to-right, workflows have a preferred top-to-bottom direction. Similar to microflows, workflows have activities and conditions. Activities come in two types: user tasks, e.g. show a page; and system tasks, e.g. send an email. One important new feature is the ability to get a result from an open page based on which button is clicked to close the page. This will be great for building approval dialogs, as you can see from the screenshot.
Workflows can have parameters just like regular microflows. In addition, each workflow has a persistent state that includes the status, current step ID, and custom data added by developers to that workflow to support their use case, e.g. orderNumber. The state can be used to store intermediary results from the various workflow activities.
It’s possible to call microflows from a workflow, but not nanoflows. On top of that, workflows can be combined in a hierarchy by calling a workflow from another workflow. To make it easier to start building workflows, Mendix will offer pre-built workflow templates that can be used a starting point and further customized to suit your needs.

Just as with microflows, workflows are a standard document in a Mendix app. They can be built in either Studio or Studio Pro, and are deployed together with the app. A single app can have multiple workflows, and workflows can span across apps by leveraging Data Hub and by calling workflows from other apps that are exposed via REST/SOAP.
For the end user, there will be a central admin area where they can see all their workflows as well as whether any action is required from the user’s side – such as approval. This central repository supports managing workflow tasks, analytics, notifications, and more.
Although this was not confirmed by Mendix, it’s very likely that like Data Hub, workflows will be a separate service outside of the standard Mendix license. No release date was given but I expect workflows to be available somewhere in Q2 2021.
That’s everything we know about workflows so far. If you have some additional insights, please share them with me and I will gladly add them to this post.
Do you have additional questions about workflows or do you have a specific use case already in mind? Let me know via Slack – I’m curious to see all kinds of scenarios that workflows can help with.
Frequently Asked Questions
Which industries does CLEVR serve?
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
How does CLEVR support digital transformation?
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
What is CLEVR's experience and reach?
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Who are some of CLEVR's notable clients?
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.