





When a customer calls the helpdesk they want help and they want it fast, right? But do they know what happened that caused their problem? And is the right information logged? Or does your Mendix application need a Flight data recorder?
The helpdesk needs to understand a problem to the level that either the solution can be given to the customer or the helpdesk can proceed looking into the problem without the customer on the phone. To get to that point the helpdesk wants to collect information (what steps did the customer take, log files), to reproduce the problem and to have access to an environment where they can play around and eventually to test the solution.
When looking at the CLEVR helpdesk for Mendix Apps I noticed two patterns. The first pattern I call: ‘show me the money’ and handles the ‘can you turn on the detailed logging’ question. The second pattern I call: ‘thinking inside the box’ and is about the ‘can you send me a database dump’ or ‘can I get access to the system’ questions the helpdesk often has to ask.
SHOW ME THE MONEY
When a customer approaches the helpdesk the first step of the helpdesk agent is focused on discovering the actual problem. Furthermore, the helpdesk agent need to know what actions the end user performed so the helpdesk can reproduce the problem. The first trouble-shooting question is always about explaining the problem to enable reproduction of the problem with a focus to actually catch the problem.
If the problem can be reproduced the helpdesk can start working on fixing it.
However, reproducing the problem is often very time consuming, or the problem cannot be reproduced at all. In addition to reproduce the problem, the next usual response to a customer problem is to look at the log files. These log files sometimes provide more technical error messages but often they do not tell you what happened, only what broke.
So the helpdesk, in the friendliest way, asks the customer to turn on more detailed logging, lets the customer wait for the problem to happen again, and then lets the customer feed the helpdesk with more information before they can fix the problem and provide a permanent solution.
This process should be more effective and less time consuming. Would it not be nice to have something similar to a Flight data recorder on an airplane that records all vital information just before the crash?
THINKING INSIDE THE BOX
A helpdesk person needs to be very good at predicting what the customer saw or which actions the customer performed. Over the phone (or mail or chat or twitter or whatever communication channel is used) the helpdesk cannot see the customer’s desk or the inside of the servers. If the software and the computers are not complex enough on their own, the helpdesk also lacks the proximity and permissions to see and touch the stuff themselves. See it as a kind of a black box around a black box. The helpdesk person needs to think inside the box he or she can’t see.
The first attempt is often to imagine what happened and then to try and see if this will happen on a local (lab) system at the helpdesk as well. If this works the helpdesk can start fixing and does not need further help from the customer for this. More often however extra information from the customer is needed.
When the helpdesk can’t imagine what happened a series of actions often happen:
- The helpdesk asks the customer for extra logging and often the customer has to ask their IT guys to deliver this
- The helpdesk asks the customer to try things and describe what happens
- The helpdesks asks for a database dump to build a situation in the lab that resembles the customer situation as much as possible
- The helpdesks visits the customer to see for themselves or asks the customer for remote access
This involves a lot of activities where the helpdesk asks the customer to deliver information. And often the customer has to ask additional IT guys to deliver the information to the helpdesk. So I started thinking what can be done to speed up things and lessen the amount of actions to be taken by the helpdesk as well as the customer. There are several options to help the helpdesk:
- Prepare helpdesk support facilities up front. Expect the logging and database dump questions and use a fast procedure to answer those questions.
- Be even more pro-active and give the helpdesk access to a database dump weekly or monthly and give the helpdesk access to the logging or to the server remotely. This is similar to the access the CLEVR helpdesk has managing a Mendix cloud node. For on premise nodes similar access needs to be arranged as well.
- Give the helpdesk extra tooling to pinpoint the problem and prevent a lot of questions.
This last option needs some more explanation. If the helpdesk does not know what the problem is they will perform an analysis of different components: The database, the server or the network and so on, and the helpdesk will ask information or logging from all those components. So I would like to give the helpdesk direct access to the information of these different components. If they can see the database log, check if the network is up and see the server stats the helpdesk can decide for themselves where to look first and whether or not they need the extra information of other logs at all.
THE SOLUTION
The options to help the helpdesk can be supported with available monitoring and logging technologies. For example remote access tools or generic APM solutions for log reading and system stats. However, often due to security restrictions the helpdesk does not get access to the components they need for analysis.
And remember, we all wanted that Flight data recorder that records all relevant information just before the crash. I have developed some Mendix specific (Flight data recorder) tools that assist the helpdesk to do a better job in diagnosing problems:
- The Trap tool that captures all information right before an error like your Flight data recorder
- The Log tool to log long term data
- The Log rerouting (tool) to capture extra detailed information
The JVM Browser (tool) to look at the java and system component from inside the application.
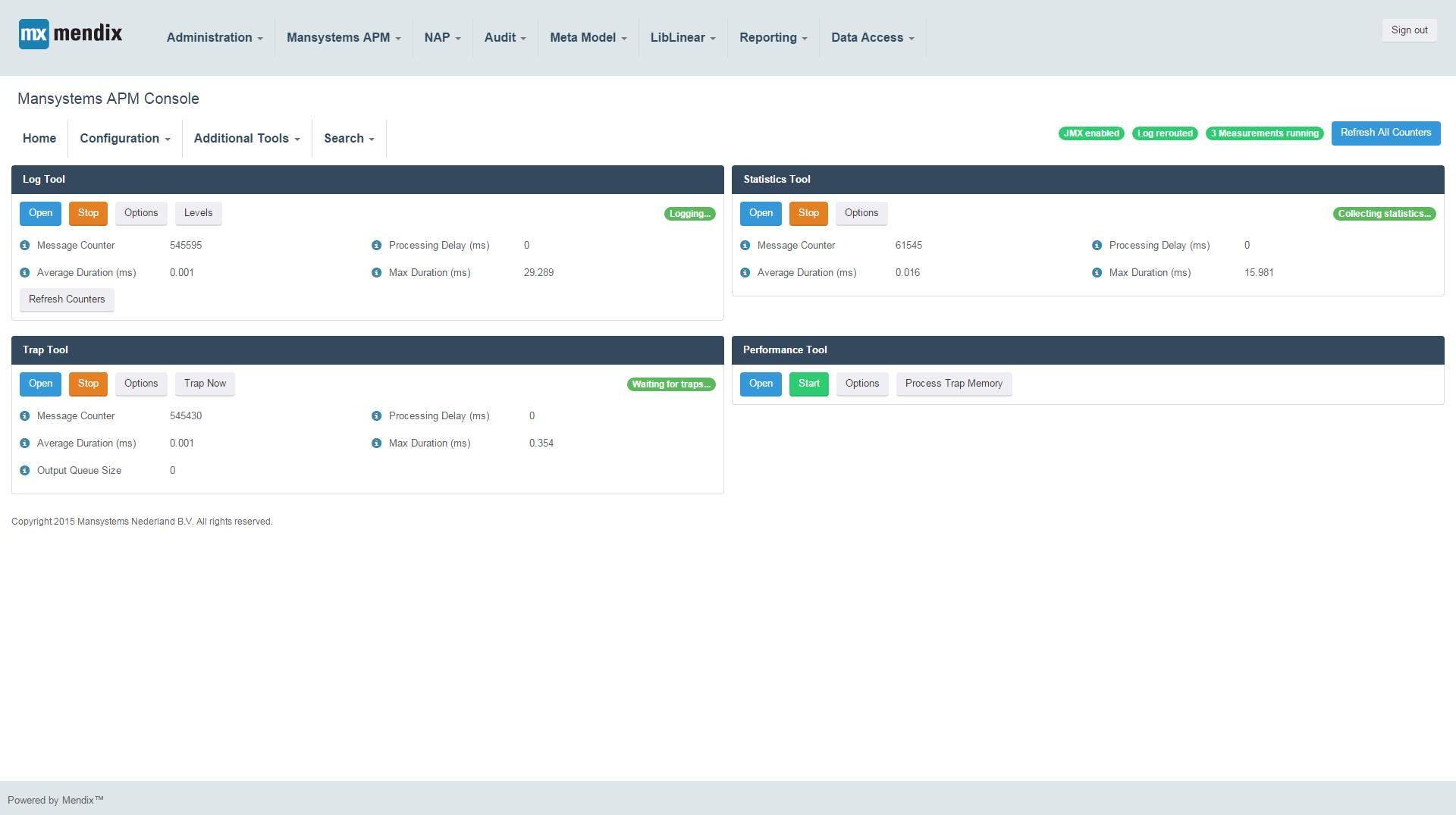
The next part of this blog describes how the trap tool, log tool, log rerouting and JVM browser help the helpdesk to perform a better job.
THE TRAP TOOL (FLIGHT DATA RECORDER)
The Mendix business server, additional libraries and custom java code generate logging. This logging can be of several levels being critical, error, warning, info, debug or trace. The last two levels, debug and trace, are especially interesting when the helpdesk is troubleshooting. However the amount of messages with level debug and trace is very high. The risk is that logging all levels all the time would overflow the system, or would let the system run out of disk space. It could make the system very slow, because resources would be used to write debug and trace messages to the disk or database.
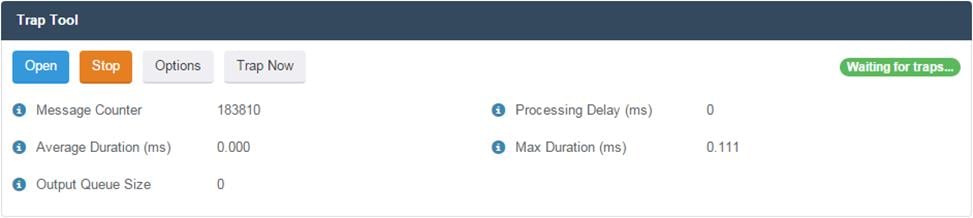
The dilemma: the helpdesk wants the debug and trace information without hampering the system too much. The answer to this is the Trap tool. This tool is listening to all levels of logging and keeping them in memory so the performance of the system is not negatively impacted by the desired logging level. Now to prevent running out of memory, the trap tool only keeps the lasts seconds in memory. So when an error message comes along the Trap tool has the last seconds before the error in memory and saves the log messages of those final seconds to the database. Does this sound like your airplane’s black box Flight data recorder or not?
THE LOG TOOL
You might ask why the helpdesk needs the log tool if they already have a Trap tool. The answer to that question is simple. There are situations where no error appears in the log and still your application doesn’t function properly.
Another answer might be that the helpdesk wants a specific log node to log for a longer period of time. The Mendix business server consists of many parts that write logging tagged as different log nodes. A log node is an indication of the source of the message. So it might be acceptable for the systems resources to select certain log nodes to log at debug or trace level for a limited amount of time.
Yet another very good reason is that the Log tool is available to the helpdesk. The helpdesk or a technical application manager can change log levels themselves. By using this tool relevant log information is available a lot faster.
LOG REROUTING
There is logging generated by non-Mendix libraries that do not end up in the Mendix logging. Java mail is an example.
The log rerouting tool listens to other logging systems and sends the log messages of those systems to the Mendix logging. This makes those messages available in the log tool and trap tool.
JVM BROWSER
Java has built-in management extensions called JMX. Those extensions can be used to get information from the JVM. This information includes startup parameters, version information, memory and CPU usage and a lot more.
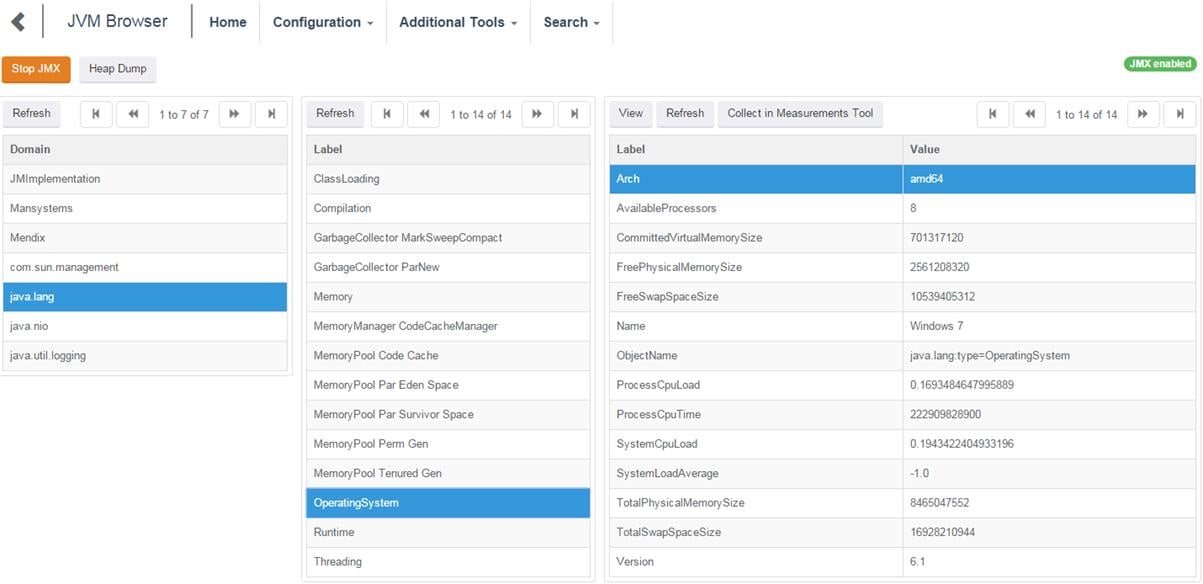
This information is normally available to java specific tools. By making this information available to the helpdesk you give them the right tool to see in which direction they should look further.
SUMMARY
In this blog I have tried to explain some come helpdesk patterns that focus on reproducibility and information collection. These are the first stages of solving issues and they were in the past time consuming activities.
By means of giving access to information to the helpdesk and by means of providing the right tools (something similar to an airplane’s black box flight data recorder that catches the last seconds of logging) you can enable your helpdesk to do their job better and faster and hopefully solve much more problems in a shorter time.
A helpdesk that uses the APM suite of Tools, is a helpdesk that can help themselves: the expected outcome is that the helpdesk can help the customer faster and better, and that what it was all about in the first place.
Do you want to learn more? Check out the first blog from Bart on application performance management.




